

Welcome to the first edition of the Outage Roundup newsletter.
Headlines
These were some of the significant outages affecting users worldwide in the last 2 weeks.
Cloudflare Outage affecting network connectivity
Started Feb 20th, this caused widespread outage on services that depend on Cloudflare.
Dependent services like Railway were affected. Railway are apparently planning to reduce dependency on them - although it’s unclear what the underlying changes are.
Overall, these 2 weeks saw another outage with Cloudflare’s Bot Management service.

Due to the sheer number of websites and SaaS dependent on Cloudflare services, an outage in any of the core Cloudflare services has a significant blast radius, as we saw in Q4 2025’s outages.
Zoom Outage affecting AI Companion Search
Zoom had an outage where some users were unable its AIC (AI Companion) Web Search. This is the 4th Zoom outage affecting AIC in the last 3 months.

Overall, Zoom has had 67 outages in the last 365 days, and 7 in the last 2 weeks.
AWS Direct Connect Outage
AWS experienced an outage with their Direct Connect service which lets customers link their private networks directly to AWS.
This is the 4th AWS outage this year, and the 35th in the last 12 months.
Although AWS is yet to publish a detailed RCA, status page updates indicate a bad deployment as the trigger.
The deployment took a while to rollout, which seems to be a good thing in this case:
"Our automated deployment takes approximately 12 hours so impact stayed limited to a subset of customers until we began observing broader impact".
Contrast this with last year's Cloudflare (Nov 2025) and Google Cloud (June 2025) outages where similar changes propagated across their global infrastructure very fast causing widespread damage.
So is a slower, controlled rollout strategy better?
Experience would certainly make it seem so. Controlled rollouts are nothing new. They have been around for a while for application releases. Cloudflare adopted it last year for configuration changes too as part of their "Code Orange" plan - instead of propagating immediately, changes would be rolled out to a limited set of locations first. If health metrics indicate things are fine, it's rolled out gradually to more and more locations. Repeat the process until the changes are rolled out across the infrastructure.

Google Workspace
Some Google Workspace users unable to load Gemini Conversations.
Started Feb 19, it’s still ongoing as of this writing. There is a suggested workaround involving manually navigating to a conversation view.
Affected Components: Gemini
Amazon Web Services : CloudFront
DNS resolution errors in CloudFront led to many dependent sites becoming unavailable.
Started 10 Feb and lasted around 7 hours.
Affected Components:
AppSync
AWS Transfer Family
AWS WAF
Amazon API Gateway
Amazon Pinpoint
Amazon Route 53
Amazon VPC Lattice
This is yet another example of an infra/CDN provider causing cascading failures in dependent services.
Other Outages
Service | Last 2 weeks | Last 12 months |
Fly.io | 13 | 180 |
Anthropic | 26 | 388 |
Cursor IDE | 12 | 130 |
Google Maps Platform | 1 | 17 |
Cloudflare | 36 | 812 |
GitHub | 20 | 234 |
Railway | 11 | 135 |
Clerk.com | 3 | 44 |
OpenAI | 13 | 337 |
Supabase | 5 | 107 |
Akamai | 4 | 82 |
Microsoft 365 | 1 | 23 |
Microsoft Azure | 1 | 31 |
Honeycomb | 2 | 30 |
DockerHub | 1 | 60 |
Google Play | 2 | 14 |
Slack | 4 | 96 |
Render | 1 | 85 |
GitLab | 5 | 128 |
Vercel | 2 | 98 |
Airtable | 3 | 23 |
Stripe | 2 | 128 |
GoDaddy | 6 | 139 |
Perplexity | 1 | 13 |
PayPal | 2 | 58 |
MailerSend | 1 | 7 |
Google Ads | 1 | 30 |
Note: Numbers include both minor and major outages.
Outages By Service Type in the Last 2 Weeks
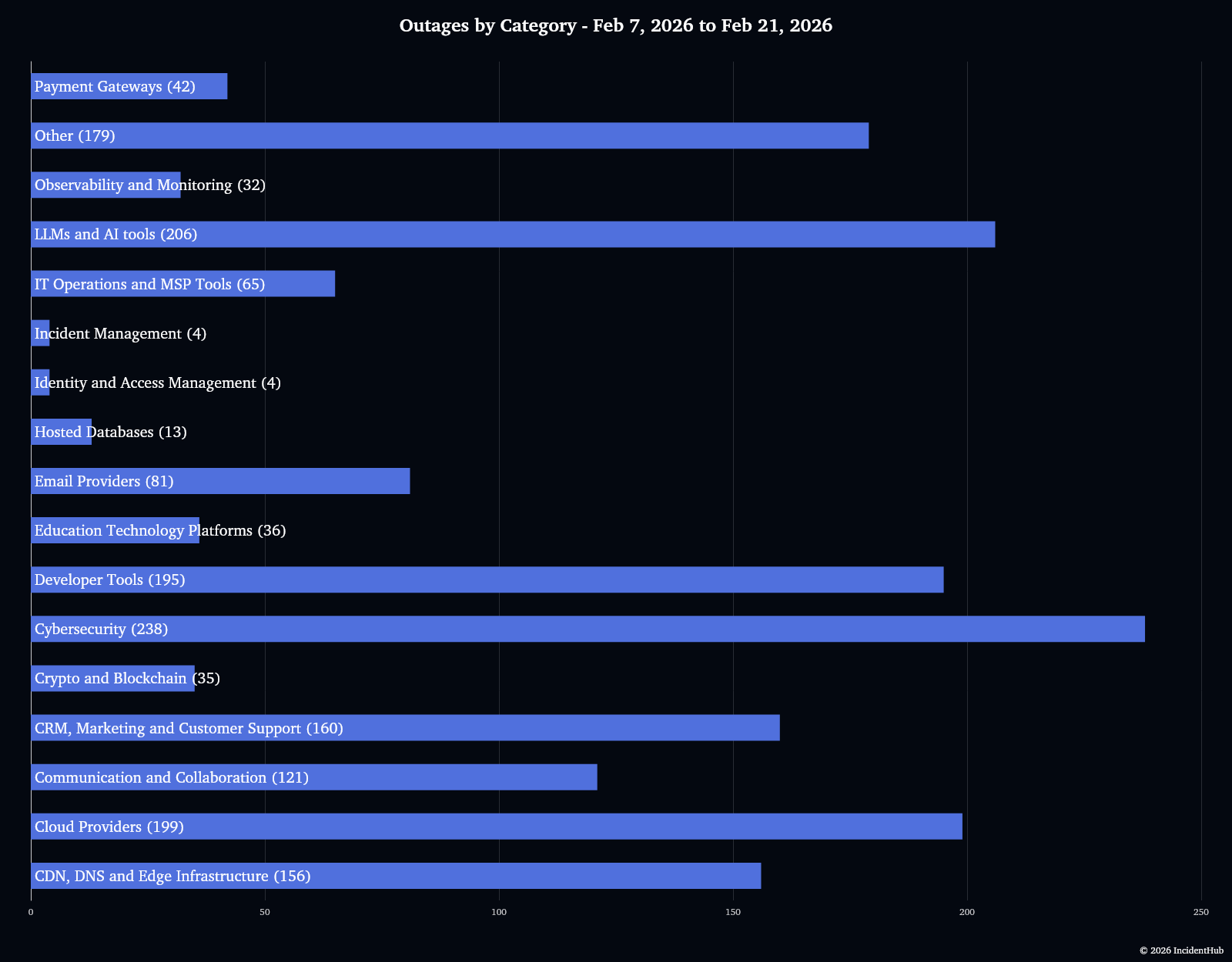
Click for larger image
In Case You Missed It…
Major Cloud Outages of 2025 - A summary of 2025’s biggest outages and their patterns.
There are reports that the AWS outage in Dec 2025 was caused by an AI agent. Amazon, however, has refuted these claims. This conversation is significant because it’s related to Amazon’s recent layoffs and increased usage of AI.
Did You Know? Microsoft Azure’s Feb 2012 outage was triggered by a software agent failing to calculate the date correctly because it did not account for that day being Feb 29th (a leap year).
Until next time,
Hrish from Outage Roundup
Visualizations and tabular data in this newsletter are derived from IncidentHub’s third-party status monitoring. IncidentHub monitors status pages of hundreds of SaaS and Cloud services.